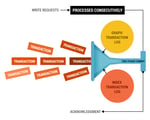
Every piece of data has its own strength and we increase its value through unified systems. These unified systems act as an enabler for data availability, thereby, resulting in smarter business decisions.
In this modern era, data is changing the face of our world. It might be helping someone to cure a disease, boost a company’s revenue or be responsible for those targeted ads you keep seeing.
In general, data is another word for information. But in the sphere of computing and business, data refers to information that is machine readable as opposed to human readable.
There are certain factors, which needs to be considered while building unified systems.
- How easy it would be to integrate a new data source?
- What formats of data can be handled?
- How easily we could build relations between different formats of data within the system?
- How complete is the data?
A Data Unification System Built Using Spark and MySql Store
Let me put forward a use case, which would help us understand the benefits of having a unified view of all the data that we have.
Consider an organization, which would process customer’s CRM information in conjunction with other data sources like their emails, twitter feeds, etc. to generate insights, which would help their customers to take better business decisions and act on them.
In the world of sales, CRM data generated by sales representatives using different available platforms, is generally messy and has lots of sparsity, which is hard to process and generate some valuable insights that benefits a sales guy and their organization as a whole.
A standardized view of such data is very important when the goal is to find associations within a tenancy and across the tenancies i.e. over the network.
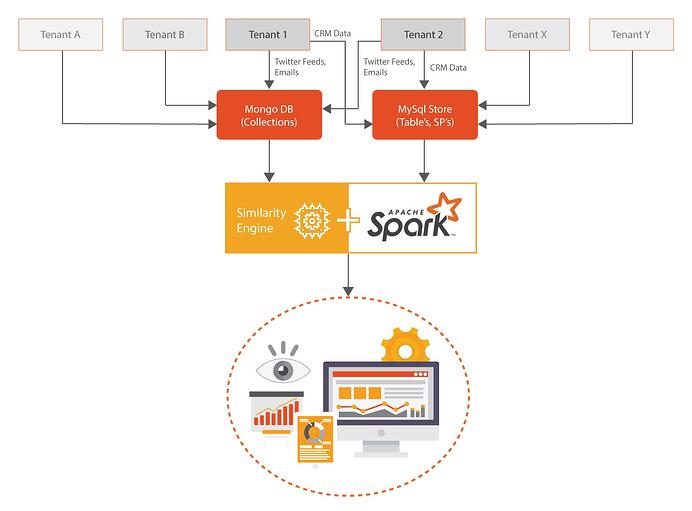
There are different ways to standardize the data. It could be accomplished by using manual data operators to clean the data or when one is dealing with volumes an automated process of reaching out to 3rd party data providers for data standardization is needed.
Once a fair amount of data standardization is achieved, one needs to compare each record with each other for identifying similar records and unifying them. This process is computationally expensive and a scalable framework like Spark will help you process big volumes within desirable latencies.
A comparison between records cannot be as straight as String Equal Match between the attributes of a record because this would unify very less number of records, and more often than not, most probable duplicate records get unified here.
A set of similar algorithms, which are fine tuned for respective attributes within a record, need to be employed to achieve unifying records that seem to be identical. Nevertheless, there are few variations in data representation.
Algorithms like FuzzyWuzzy, Jaccard’s Similarity, Dameru Levenshtein etc. with fine-tuned thresholds will help us in achieving the goal.
By unifying data, we achieve more information for an entity, which would help us in taking a deterministic call in associating information related to this entity from other source.
A component like Apache Drill can query information related to an entity from different available sources in the system to generate valuable insights, which could lead to constructive business decisions.
Innominds has in-depth experience in providing Integrated Big Data as a service that provides core capabilities in lifecycle management, data collection and unstructured data processing. We combine context-aware analytics with databases and data processing, helping our clients create a meaningful user experience for their customers. We solve Big Data challenges by developing solutions with platforms and components that assist in extracting insights for predictive operations.
Interested! For any demos or POCs, please write to us at marketing@innominds.com and know more about our offerings.