Introduction
Neo4J is one of the most popular graph databases. But, unfortunately, ingesting large volumes of data take a lot of time as Neo4J tries to acquire lock on nodes before it creates/updates a node.
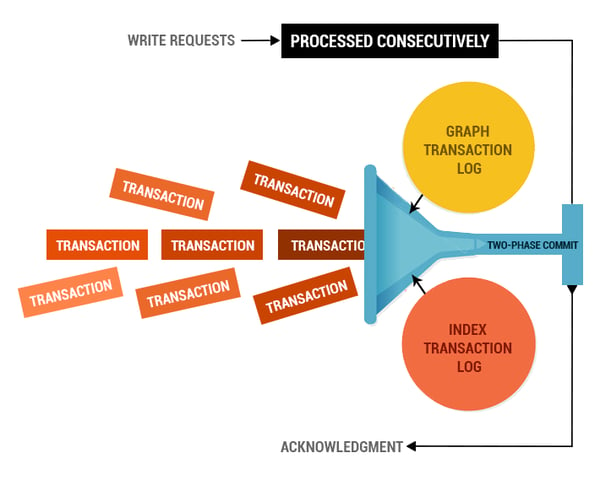
The situation is worse when it comes to ingesting edges. To create or update an edge, Neo4J transaction manager acquires a lock on both the nodes and creates/updates the edge. Now, imagine a scenario wherein there are multiple edges that are being pushed at the same time via multiple transactions.
Let’s take a hypothetical scenario. An edge between nodes A and B and the edge between nodes B and C is to be pushed in two different transactions. In this case, the first transaction tries to acquire a lock on Node A and Node B and tries to create or update the edge. But the second transaction would fail, as it cannot acquire lock on Node B.
The solution to this problem is to ingest the data sequentially, if there is a possibility of having interdependent data, which is not possible in this big data world.
How Did We Solve This Problem?
Neo4J supports data ingestions using CSVs. The CSVs can be a local file on the server of Neo4J or can be streamed on top of HTTP layer.
Here, AKKA was chosen as handling back pressure from Neo4J is inherently built into it. Neo4J back pressure depends on the memory buffer of its server. Currently, our Neo4J server on AKKA handles an ingestion loads of around 1 million nodes/edges per 2 mins 12 secs, which was couple of hours without this approach to push data sequentially.
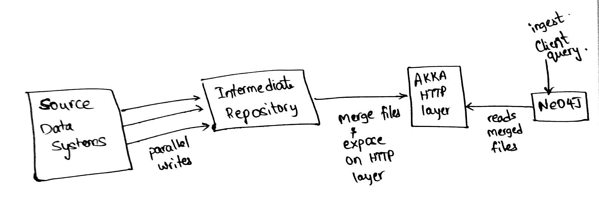
In this case, the source data system is Hive and intermediate repository is HDFS. The data from Hive is queried in parallel for all the different types of nodes/edges and persisted as CSVs in the intermediate store.
Later, the ingest process kicks in, which would merge the multiple CSV files and expose them on top of HTTP layer.
Then, a query is triggered on top of Neo4J to pull in the data via HTTP layer and ingest the same.
Sample AKKA HTTP Codeblock:
import akka.actor.ActorSystem
import akka.http.scaladsl.Http
import akka.http.scaladsl.server.Directives._ import akka.stream.ActorMaterializer
object Main {
def main(args: Array[String]): Unit = { try {
implicit val actorSystem = ActorSystem("system")
implicit val materializer = ActorMaterializer()
val routes = pathPrefix("files" / Segment) { fileName => println(s"requested file ${fileName}")
val file = s"/home/sbeathanabhotla/spark/$fileName"
getFromFile(file)
}
Http().bindAndHandle(routes, "0.0.0.0", 7111)
println("server started at 7111")
} catch {
case ex: Exception => { ex.printStackTrace()
}
}
}
}
Sample Ingestion Query:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM " http://site-edge01.dev.slc1.ccmteam.com:7111/files/orgs.csv">http://site-edge01.dev.slc1.ccmteam.com:7111/files/orgs.csv "
AS line MERGE(org:Organization {org_guid: line.org_guid, org_nm: coalesce(line.org_nm,"")});
Innominds has in-depth experience in providing Integrated Big Data as a service that provides core capabilities in lifecycle management, data collection and unstructured data processing. We combine context-aware analytics with databases and data processing, helping our clients create a meaningful user experience for their customers. We solve Big Data challenges by developing solutions with platforms and components that assist in extracting insights for predictive operations.
Interested! For any demos or POCs, please write to us at marketing@innominds.com and know more about our offerings