Introduction
The Convolutional Neural Network (CNN), one of the deep learning models, has seen a lot of success in a variety of computer vision applications. The current approach of deciding a CNN architecture and tuning the hyperparameters of it is either decided by heuristics or by trial and error.
Trial and error are a tedious and resource intensive process, as the Neural Network has to be trained and validated for multiple configurations. To address this problem, we go through the algorithm discussed in this document that is built using reinforcement learning approach. It would optimally find Neural Network architecture and its hyperparameters.
Here, we focus on designing neural architectures for image classification tasks, but the solution is generic and can be extended not only to image classification and CNNs but to any neural network architecture.
The reinforcement learning agent is trained to choose layers of CNN sequentially using an algorithm of Reinforcement Learning namely Q-Learning with an epsilon-greedy exploration strategy and experience replay memory. The agent explores a finite but large space of possible architectures and discovers network architectures with improved performance.
On image classification benchmarks, the agent-designed networks beat existing networks (consisting of only similar layers) that are competitive against the state-of-the-art methods that use more complex procedures to obtain results.
Architecture Overview
The agent starts off by randomly choosing a layer to build a network based on its heuristic experience. Since there isn’t a past experience to fall upon, some layers would be chosen at random to build a network. The chosen network is then trained on the given dataset; the network's definition and accuracy are stored in the agent’s replay memory. The agent uses these memory instances to learn about the network layers through an algorithm called Q-Learning. Finally, the agent decides on the layers and their stacking after iterations.
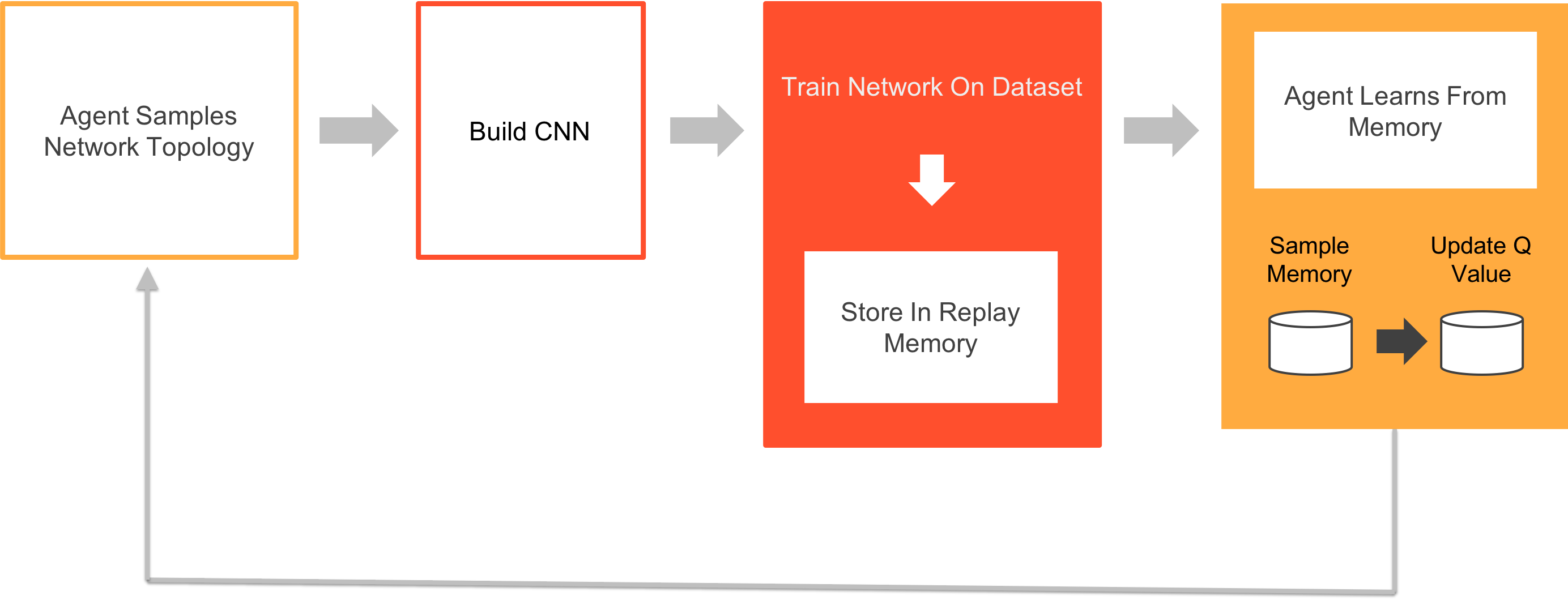
In the above shown architecture, we train the Reinforcement Learning (RL) agent as it picks network layers sequentially. We consider the sequential layer selection process as a Markov Decision Process. The agent selects layers sequentially through a strategy called the epsilon-greedy strategy. The layers are selected until a termination condition is reached.
The network proposed by the agent is trained on the dataset, and the agent is rewarded with a value equal to the test accuracy. The test accuracy and network definition are stored in a memory, which is technically called replay memory. Sampling is done periodically on the replay memory to update Q-Matrix. The agent follows a schedule for the exploration strategy, which determines if the agent is exploring the state space or picking layers as exploitation.
This method requires three main design choices:
- Representing network definitions as string
- Defining a valid set of action space, i.e., the valid layers that the agent can pick given its current state
- The amount of state-action space that the agent can explore before the agent can settle on an architecture
Experiment Details
During the exploration phase when the value of ∈ is high, each network is trained with a relatively fast training schedule. For each run, a validation dataset is chosen from the training set randomly, yet, maintaining the class distribution.
For each network proposed by the RL agent, a dropout layer was added after every DENSE layer. For the sake of mathematical discussion, out of n dropout layers added to the network, ith dropout layer, would have a dropout probability of i/2n.
Every proposed network was trained for 20 epochs with optimizer as Adam. Since we had the luxury of having big enough GPUs, the training batch size was set high to 128 and the learning rate (alpha) was set to 0.001. This is because there won’t be much to learn in the initial exploratory phases.
For the models that performed better than the previous models, the learning rate would be reduced to 80% of its value every 5 epochs in order to avoid overfitting of data. The experiments took five days to complete for each dataset with 10 NVIDIA K10 GPUs. In order to train the models quickly, the data parallelism of Keras models was put into use.
After the epsilon schedule is completed by the agent, top 10 models found over the course of time were selected. The selected models were then fine-tuned with a longer training process, and then top five high performance models were ensembled.
Results Comparison
Prediction Performance: We compare the accuracy of the networks proposed by Q-Learning based algorithm with the methods that are proposed as best in class on three openly available datasets. The accuracies reported are of the best model and the ensemble of the top five models. Taking a step backward, below is the table comparing the error rate of the networks proposed by the Q-Learning agent with the networks proposed in various papers consisting of similar layer types.
|
Method/Paper |
CIFAR-10 |
SVHN |
MNIST |
|---|---|---|---|
|
Maxout Networks |
9.38 |
2.47 |
0.45 |
|
Network in Network |
8.81 |
2.35 |
0.47 |
|
FitNets: Hints for Thin Deep Nets |
8.39 |
2.42 |
0.51 |
|
Current Approach |
7 |
3 |
0.32 |
As seen in the table, our model has better accuracies when compared to all other similar models. Now, we will go ahead and compare the accuracies of our architectures with six top network architectures, though they have complex layer types and design ideas. The complex design ideas include generalized pooling operations, residual connections, and recurrent networks. Our results are competitive with these methods too. We can finally see that our proposed method performs better than existing automated network design methods.
|
Method/Paper |
CIFAR 10 |
SVHN |
MNIST |
|---|---|---|---|
|
Drop Connect |
9.32 |
1.94 |
0.57 |
|
Deeply supervised nets |
8.22 |
1.92 |
0.39 |
|
Recurrent convolutional neural network for object recognition |
7.72 |
1.77 |
0.31 |
|
Current Approach (ensemble) |
7.32 |
2.06 |
0.32 |
|
Current Approach (best model) |
6.92 |
2.28 |
0.44 |
|
Tree+Max-Avg |
6.05 |
1.69 |
0.31 |
Conclusion
Neural networks are increasingly getting popular in a variety of use cases and domains, thus increasing the necessity to build scalable problem specific networks. We are approaching towards this goal using reinforcement learning and are able to generate CNNs for various image classification tasks.
We even saw that the networks designed using Reinforcement Learning techniques outperform previous approaches and manually designed networks, which uses similar layer types. The proposed solution can be applied to supervised set of problems like classification and regression. This can also be applied to unsupervised set of problems like autoencoders, clustering, etc.
The objective of the proposed solution is to demonstrate the possibility of automatically designing CNNs for classification compatible accuracies and efficiencies.
This method can be further extended to solve constraint-based network design like optimizing size, speed, etc. For example, the agent was not allowed to create models larger than the insisted limit. We can even penalize the agent for proposing a network that has slow forward passes or add more rewards to quick forward pass networks. In the discussed algorithm implementation, same layers and hyperparameters were used to design networks of different datasets. This approach can give way to better algorithms like policy gradient to quickly converge and design network.
As the resources like hardware are increasingly becoming cheaper and easily available, many other hyperparameters can be explored like adding more number of layers and residual nature to the network, and possibility of having different activation functions at each layer apart from ReLU.
One interesting way in which this solution can be taken forward is to learn hyperparameters of the network in a conditional way rather than trying to learn unconditionally.
However, the proposed method requires high computational power; the job with default settings took approximately five days on our research cluster. We can sample the training data to a small size to reduce the computational time. Thus, Q-Learning can be used to develop paths to reduce the computational power needed for a network selection. For example, start with a sample of the dataset and as the iterations increases, the data size can be increased. Moreover, we can consider applying regularization techniques to simplify the CNN architectures.
About Innominds
Innominds is a leading Digital Transformation and Product Engineering company headquartered in San Jose, CA. It offers co-creation services to enterprises for building solutions utilizing digital technologies focused on Devices, Apps, and Analytics. Innominds builds better outcomes securely for its clients through reliable advanced technologies like Blockchain, Big Data, Artificial Intelligence, DevOps and Enterprise Mobility among others.
From idea to commercialization, we strive to build convergent solutions that help our clients grow their business and realize their market vision.
Interested! For any demos or project discussions, please write to us at marketing@innominds.com and know more about our offerings.